AI编码效率翻倍,公司业务为啥没感觉?阿姆达尔定律揭露AI编程提效天花板
近期,大模型的爆发和AI编程工具的发展,实实在在降低了编码门槛,样板代码、接口实现、单元测试这类重复性工作,综合产出效率普遍能达到原来的 1.5~2 倍。但与此同时,另一个体感悖论也越来越突出 ——代码写得更快了,项目上线速度、公司整体交付效率,却完全没有出现同比例的提升,很多团队甚至感觉评审、测试环节反而更堵了。
这不是管理失当,也不是 AI 不够强。早在半个多世纪前,计算机科学家吉恩・阿姆达尔提出的一条经典定律,就精准预言了今天的局面。
一、阿姆达尔定律:局部提速永远不等于全局胜利
1967 年,IBM 科学家吉恩・阿姆达尔在研究并行计算性能时,提出了一个简洁却极其深刻的结论:一个系统的整体性能提升上限,永远由其中无法被优化的部分所决定。
它的数学表达式非常经典:
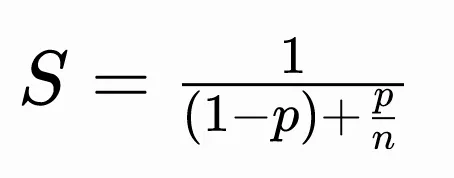
其中:
S 是系统整体的加速比,也就是总效率提升的倍数
p 是可被优化环节在总流程中的时间占比
n 是该环节获得的加速倍数
这条定律最反直觉的地方在于:哪怕你把某一个环节加速到无限快,整体效率也存在无法突破的天花板,这个天花板恰恰来自那些 “提速不了” 的部分。
举个最经典的例子:如果一个程序有 30% 的代码可以并行优化,剩下 70% 必须串行执行,那么哪怕你投入无限多的 CPU 核心,把并行部分的耗时压缩到趋近于 0,整个程序的运行速度最多也只能提升约 1.43 倍。剩下 70% 的串行逻辑,就是无法逾越的硬瓶颈。
这个规律不仅适用于芯片与程序,同样完全适用于企业的运转流程。
二、先看研发内部:编码效率翻倍,研发整体能快多少
我们先把范围限定在研发部门内部,看看 AI 编程的提效在研发全链路中会被稀释到什么程度。
一个完整的软件研发交付链路,从来不是只有 “写代码” 这一件事。我们把从需求到上线的完整周期拆解开来,大致可以分为以下环节:
| 环节 | 占总研发周期比例 | AI 编程的实际加速效果 |
|---|---|---|
| 需求调研与产品设计 | 25% | 几乎无法加速,核心是业务理解与决策 |
| 技术方案与架构评审 | 15% | 几乎无法加速,核心是权衡与判断 |
| 编码实现 | 30% | 显著加速,即行业普遍感知的 2 倍提效 |
| 代码评审与调试 | 15% | 仅部分加速,核心质量把关仍依赖人 |
| 测试与质量保障 | 10% | 仅部分加速,核心场景验证无法替代 |
| 部署与跨团队对齐 | 10% | 几乎无法加速,依赖流程与协作 |
我们用普遍认可的务实假设代入公式:编码环节效率真的提升 2 倍,可优化部分占比 30%。
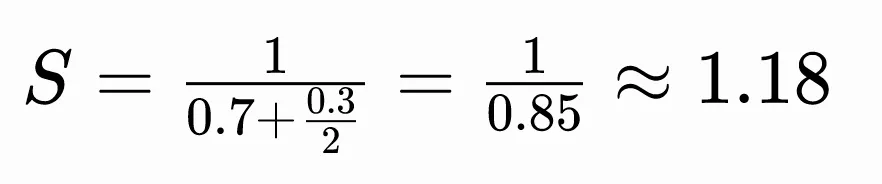
结论非常直观:编码效率提升 2 倍,研发部门的整体交付效率大约只能提升 18%。
如果团队的需求更复杂、评审更严格、跨团队协作更多,编码占总周期的比例会进一步降低到 20%,那么整体提升会缩水到约 11%。
更值得关注的是极限天花板:就算未来 AI 进化到写代码完全不花时间,研发整体效率的上限也只有约 1.43 倍。只要需求澄清、架构设计、代码评审、质量把关这些环节还是原来的节奏,研发效率就永远不可能翻倍,更别说达到 2 倍以上。
三、放大到全公司:审批与业务流程才是真正的天花板
如果把视角再拉高一层,站在整个公司的运转效率来看,AI 编程的收益会被进一步稀释。
讨论公司级效率,真正有意义的指标是端到端价值交付周期—— 从业务部门产生一个想法、提交需求,到走完立项、审批、研发、验收、落地全流程,最终产生业务价值的完整耗时。它串联了业务、财务、合规、研发、运营等所有部门,也包含了各类审批、等待、对齐的隐性成本。
我们以流程完善的中大型企业为原型,把完整链路拆解为三大阶段共 10 个核心环节,逐一评估 AI 编程对它们的实际影响:
| 大阶段 | 具体环节 | 占总周期比例 | AI 编程的有效加速倍数 |
|---|---|---|---|
| 业务立项与审批 | 业务调研、需求构思、内部对齐 | 12% | 1(完全无影响) |
| 立项评审、预算申请、层级审批 | 10% | 1(完全无影响) | |
| 合规、法务、安全前置审核 | 8% | 1(完全无影响) | |
| 研发交付 | 产品设计、技术方案与架构评审 | 12% | 1.1(仅微弱辅助) |
| 编码实现 | 15% | 2(显著加速) | |
| 测试、代码评审、缺陷修复 | 10% | 1.5(部分加速) | |
| 发布审批、上线与变更管控 | 3% | 1(基本无影响) | |
| 业务落地与结项 | 业务验收、UAT 用户测试 | 8% | 1(完全无影响) |
| 运营推广、用户培训、流程切换 | 7% | 1(完全无影响) | |
| 财务结算、项目结项归档 | 5% | 1(完全无影响) | |
| 隐性成本 | 跨部门对齐、排期等待、会议沟通 | 10% | 1.05(微弱间接优化) |
一个扎心的事实是:在整个公司的端到端周期里,真正能被 AI 编程显著加速的 “编码实现” 环节,仅占总周期的 15%。剩下 85% 的时间,分布在业务决策、行政审批、合规风控、验收落地、组织协作中,全都和 “写代码快不快” 没有直接关系。
我们代入扩展版阿姆达尔公式计算,可以得到两种典型企业场景下的真实收益:
场景一:中大型 / 强监管企业(重流程、多审批)
这类企业常见于医疗、金融、政务、大型制造行业,审批链条长、合规要求高、跨部门协作成本高。
按上述占比计算后,优化后的总周期约为原来的 87.6%,整体加速比约为 1.14,即全公司运转效率提升约 14%。
就算编码环节耗时趋近于零,整体效率的极限天花板也只有约 1.25 倍。换句话说,哪怕 AI 免费写完所有代码,只要公司的审批、决策、验收流程不变,整体效率最多提升 25%,永远不可能翻倍。
计算过程:
| 序号 | 环节 | 时间占比 $t_i$ | 加速倍数 $n_i$ |
|---|---|---|---|
| 1 | 业务调研、需求构思、内部对齐 | 0.12 | 1 |
| 2 | 立项评审、预算申请、层级审批 | 0.10 | 1 |
| 3 | 合规、法务、安全前置审核 | 0.08 | 1 |
| 4 | 产品设计、技术方案与架构评审 | 0.12 | 1.1 |
| 5 | 编码实现 | 0.15 | 2 |
| 6 | 测试、代码评审、缺陷修复 | 0.10 | 1.5 |
| 7 | 发布审批、上线与变更管控 | 0.03 | 1 |
| 8 | 业务验收、UAT 用户测试 | 0.08 | 1 |
| 9 | 运营推广、用户培训、流程切换 | 0.07 | 1 |
| 10 | 财务结算、项目结项归档 | 0.05 | 1 |
| 11 | 跨部门对齐、排期等待、会议沟通 | 0.10 | 1.05 |

场景二:研发驱动型轻流程公司
如果是产品驱动的互联网科技公司,决策扁平、审批少、业务与研发高度对齐,研发环节占比会更高。调整参数后计算,整体效率提升约 20%,极限天花板约为 40%。这已经是非常理想的结果。
计算过程:
| 序号 | 环节 | 时间占比 $t_i$ | 加速倍数 $n_i$ |
|---|---|---|---|
| 1 | 业务立项与审批合计 | 0.15 | 1 |
| 2 | 产品设计、技术方案与架构评审 | 0.12 | 1.1 |
| 3 | 编码实现 | 0.20 | 2 |
| 4 | 测试、代码评审、缺陷修复 | 0.15 | 1.5 |
| 5 | 发布审批、上线与变更管控 | 0.03 | 1 |
| 6 | 业务落地与结项合计 | 0.25 | 1 |
| 7 | 跨部门对齐、排期等待、会议沟通 | 0.10 | 1.05 |

四、现实更骨感:三个吃掉效率的反作用
以上还只是理论上的乐观估算。真实落地中,有三个普遍存在的反作用,会进一步抵消 AI 编程带来的收益,甚至让整体效率不升反降。
1. 代码膨胀导致评审与测试拥堵
AI 让代码产出速度翻了 2 倍,但评审代码的人、做核心逻辑验证的人并没有同步增加。原来一天 5 个 PR 可以按时审完,现在一天产出 10 个 PR,代码评审队列直接拉长;测试用例可以批量生成,但核心场景的验证、业务逻辑一致性校验依然依赖人力,大量产出的代码卡在下游环节,形成库存。很多团队的体感是:代码写得快了,卡在 CR 和测试的时间反而更长了。
2. 需求变更泛滥,返工成本飙升
编码成本变低后,业务侧很容易产生 “先做出来看看” 的心态,频繁提出变更、反复调整方向。原本需要想清楚再开工的需求,变成了边做边改,大量 AI 生成的代码被推翻废弃。编码省下的时间,全被额外的返工成本吃掉了,这是组织层面最常见的 “效率陷阱”。
3. 技术债累积,透支长期效率
AI 生成的代码往往偏向 “快速可用”,在架构一致性、可维护性、可扩展性上容易打折扣。短期看交付速度上去了,但长期来看系统会越来越难修改,后续需求的开发效率会逐步下降,相当于用未来的效率换取了当下的速度。
把这三个因素纳入考量,很多重流程企业的实际效率提升往往只有 8%~12%,管理失当的团队甚至可能出现负收益。
五、真正的启示:别在编码上死磕,去优化真正的瓶颈
理解了阿姆达尔定律在企业运转中的映射,我们就能跳出 “AI 能不能提效 2 倍” 的无意义争论,得到三个更有价值的结论。
第一,别对 AI 编程的组织价值抱不切实际的期待。
AI 编程是强大的研发提效工具,但它不是解决公司效率问题的银弹。它优化的只是全链路中的一个局部环节,而且往往不是瓶颈环节。指望靠几款 AI 编码工具让公司整体效率翻倍,和指望换个更快的火花塞解决堵车问题一样荒谬。
第二,AI 真正的价值是释放人力去攻坚瓶颈。
编码效率提升 2 倍,不意味着可以裁掉一半的工程师。正确的打开方式是:把工程师从重复的编码劳动中解放出来,让他们把时间投入到真正决定交付速度的瓶颈上 —— 更前置地介入业务、减少无效需求、打磨系统架构、推动流程自动化、完善质量体系。把省下来的编码时间,拿去优化那 85% 的串行部分,整体效率才会真正上台阶。
第三,未来的效率竞争,拼的是全流程的 AI 渗透。
只在编码环节卷 AI,很快就会触碰到阿姆达尔天花板。真正能拉开差距的,是那些能把 AI 能力渗透到需求分析、方案设计、评审校验、测试验证、合规审核、流程审批全链路的团队。当每个环节都获得一定程度的加速,整体效率才会出现量级的跃迁。
六、结语
AI 编程带来的 2 倍效率是真实的,但它只发生在代码工程师的键盘上。而一家公司的运转效率,藏在会议室的决策里、层层审批的流程里、跨部门的协作里、业务落地的执行里。后者不进化,前者再快也只是徒劳。
局部工具再强大,也替代不了组织层面的进化。这大概就是所有技术工具都绕不开的终极宿命。