一、左右耳机是如何配对的
一直以来,我都以为FreeBuds的左右耳是唯一绑定的。有一次听到一个音频节目,了解到闲鱼上有售卖单个耳机的商家,这才发现,同型号、同固件版本的FreeBuds是可以重新绑定配对的。
Learn and share.
一、左右耳机是如何配对的
一直以来,我都以为FreeBuds的左右耳是唯一绑定的。有一次听到一个音频节目,了解到闲鱼上有售卖单个耳机的商家,这才发现,同型号、同固件版本的FreeBuds是可以重新绑定配对的。
在单机文件系统中,删除文件是一个“即时生效”的动作:执行删除操作后,文件元数据直接清除、磁盘空间立刻释放,逻辑简单、用户感知直观。但在大数据分布式集群中,这一逻辑不再适用,也是最容易让开发者产生认知偏差的核心点。
如果针对亿级小文件采用“即时物理删除”机制,会瞬间产生海量随机IO、频繁的元数据变更、大规模块数据清理动作,直接引发集群IO抖动、节点负载飙升、读写任务阻塞,严重破坏集群稳定性。
寻址,是数据读写的核心链路,也最能体现大数据分布式系统与传统单机系统的设计取舍。
在单机时代,文件寻址遵循“路径直连”逻辑:文件路径对应唯一inode,操作系统直接定位磁盘扇区,链路短、开销小、速度快。但这套逻辑完全无法适配大数据海量小文件场景——如果亿级小文件都依靠“直连寻址”,中心元数据节点极易成为瓶颈,集群调度、读写IO会导致严重延迟。
因此,所有主流大数据系统都做出了统一的核心取舍:牺牲单次寻址的极致速度,用多层索引、分层过滤、元数据跳转的微小计算开销,换取整个集群的稳定性与无限伸缩性。
在大数据分布式存储场景中,小文件是业界公认的“甜蜜的毒药”。单个KB级小文件体量微小、读写开销极低,看似不会对集群造成压力,但当业务持续迭代,千万级、亿级小文件批量堆积后,会引发一系列连锁集群故障:撑爆元数据节点内存、大幅拖垮集群整体读写性能、造成计算任务调度拥堵,严重时直接导致整个大数据集群服务瘫痪。
小文件治理的核心痛点,并非单文件数据量过小,而是传统单机文件的独立存储逻辑,完全不适用于分布式海量数据架构。单机场景下的小文件独立存储、独立管理模式,会无限放大分布式集群的元数据压力、存储冗余、计算调度缺陷。
基于此,HDFS、Hive、HBase、Ceph、Iceberg、Delta Lake、Hudi等所有主流大数据存储系统,针对小文件存储形成了统一的核心优化思路:彻底杜绝小文件以独立文件形态落地,通过文件打包、数据转译、结构化元数据管理、增量追加写入等方式,从根源减少物理文件数量,消解元数据膨胀隐患。不同系统因适配的业务场景不同,小文件存储的底层实现逻辑存在显著差异,本章节将深度拆解各主流系统的小文件存储机制。
对于需要用Windows办公的很多工程师而言,Windows Subsystem for Linux (WSL) 早已从最初的“玩具”蜕变为不可或缺的生产力工具。相信很多同学都知道WSL有两个版本,但多数同学并不清楚WSL1和WSL2的区别,咱们今天来介绍一下。
WSL1是Windows平台下Linux翻译层,Wine是Linux平台下Windows翻译层,两者有很多相似之处,本文介绍一下两者的异同点。
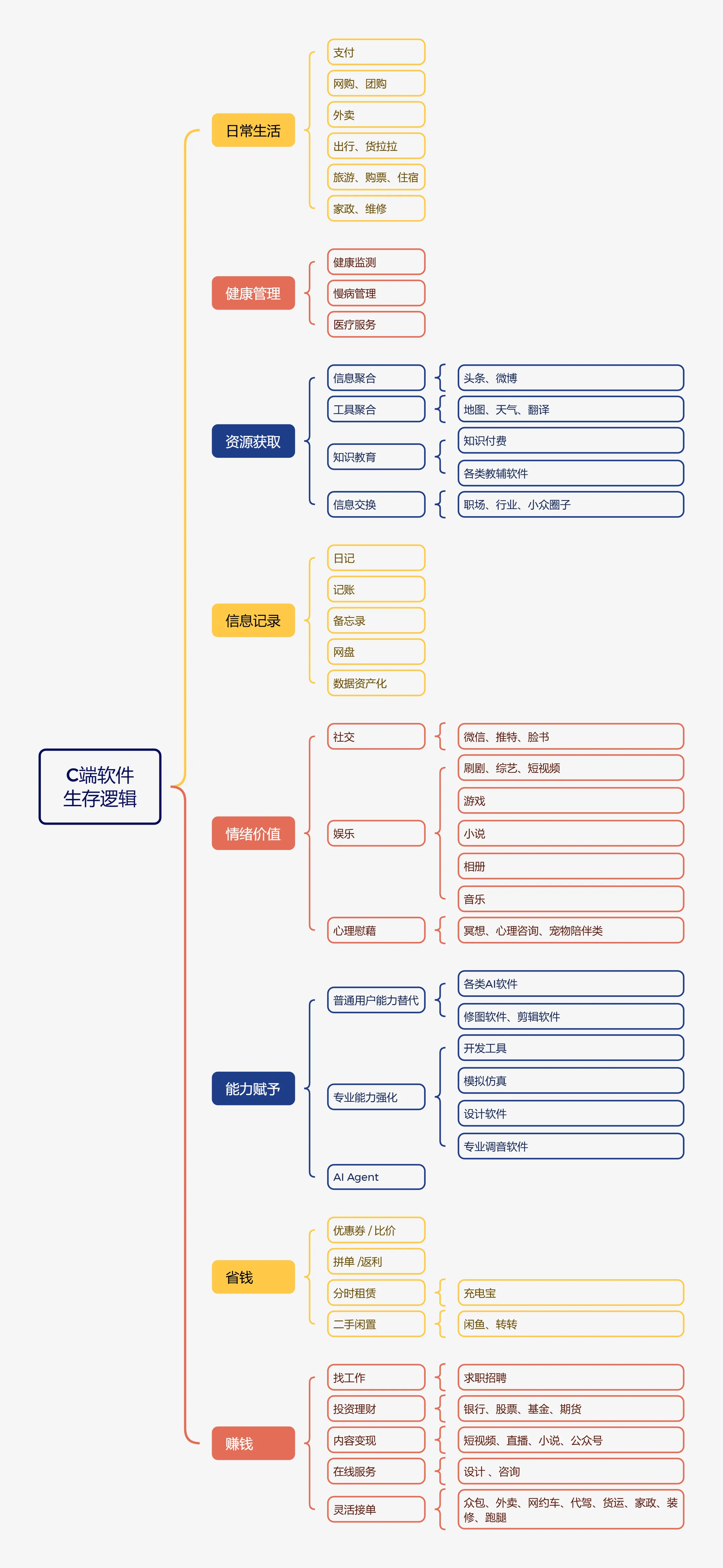
C 端软件的核心生存逻辑,是精准切入个人用户的高频刚需或强价值场景,先为用户创造明确价值(提效、省钱、获利、情绪满足等)建立用户依赖,再通过广告、交易抽成、会员付费、增值服务等模式完成商业闭环。各模块的具体生存逻辑如下:
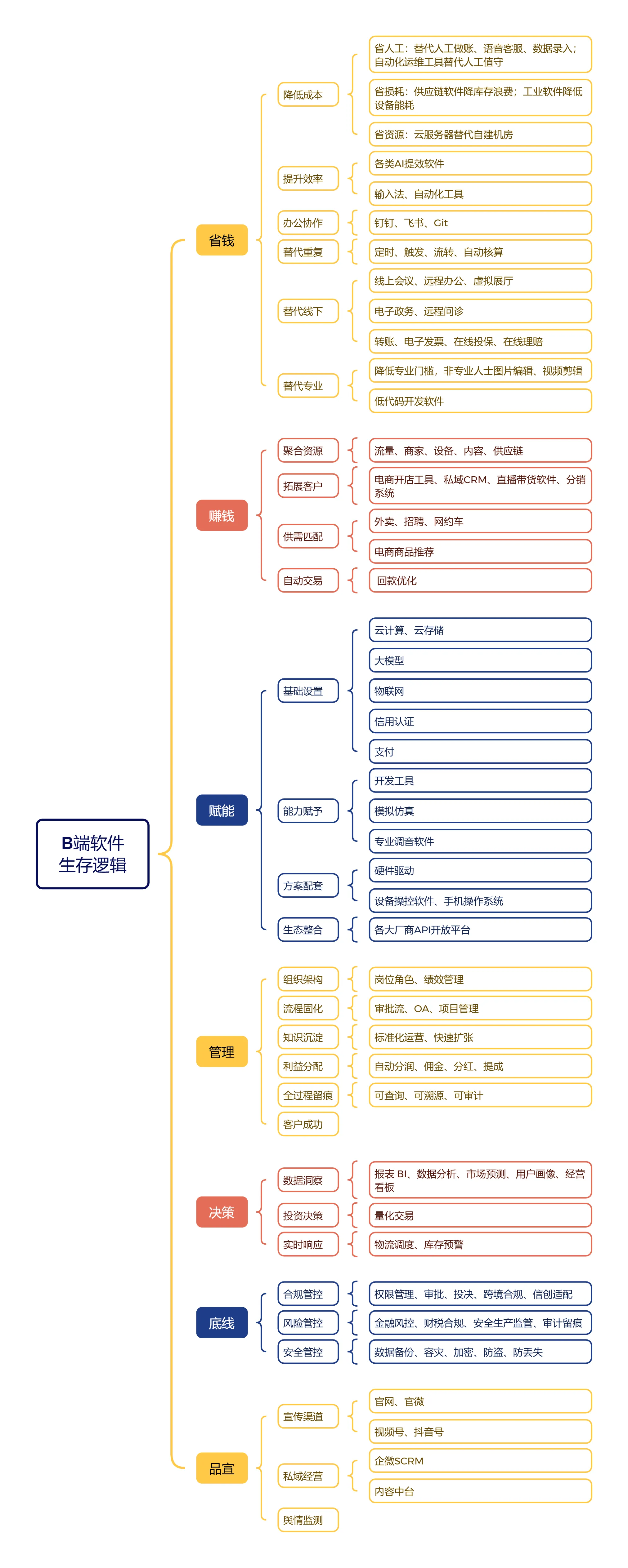
B 端软件的核心生存本质,是面向企业组织创造可量化的商业价值:企业付费决策高度理性,核心衡量标准是投入产出比(ROI)—— 软件支出要么换来成本缩减,要么带来营收增长,要么守住合规与安全底线,最终通过业务深度绑定形成高迁移成本,实现持续续费、增购的长期存续。
智能手表和穿戴设备通过集成多种微型传感器,结合算法模型,实现了对人体多项生理指标的实时监测,凭借便携性、连续性优势,成为日常健康管理的重要辅助工具。以下是主要检测指标及其实现原理、细节与应用说明:
在桌面端应用开发领域,跨平台技术正逐步替代传统原生开发,成为降低多端(Windows、macOS、Linux)开发成本、提升迭代效率的核心选择。当前主流的桌面端跨平台解决方案各具特色,本文将聚焦六大方案——Electron、Tauri、Flutter、ReactNative(RN)、.NET MAUI、QT的桌面端适配特性,从核心原理、优缺点、适用场景三个维度进行全面对比,为桌面端开发者的技术选型提供专业参考,厘清各方案在桌面端的核心差异与适配边界。