16. DeepSeek V3.2
本文以 2024 年 12 月发布的 DeepSeek V3 开篇。那段时间 DeepSeek 陆续推出了多款模型,但我大多没有展开介绍,因为它们都不属于 DeepSeek V3、DeepSeek R1 这类重磅旗舰级模型发布。
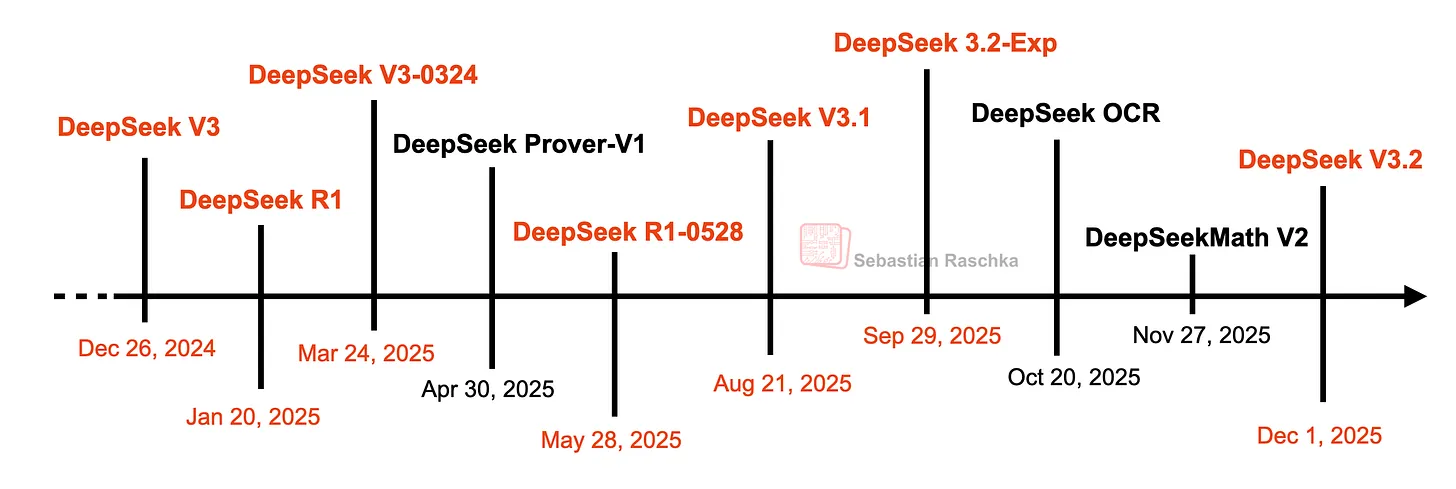
不过,DeepSeek V3.2 是一次极具分量的更新:在部分基准测试中,它的表现已与当前的 GPT-5.1 和 Gemini 3.0 Pro 模型持平。
它的整体架构与 DeepSeek V3 相近,但团队新增了稀疏注意力机制以进一步提升运行效率。
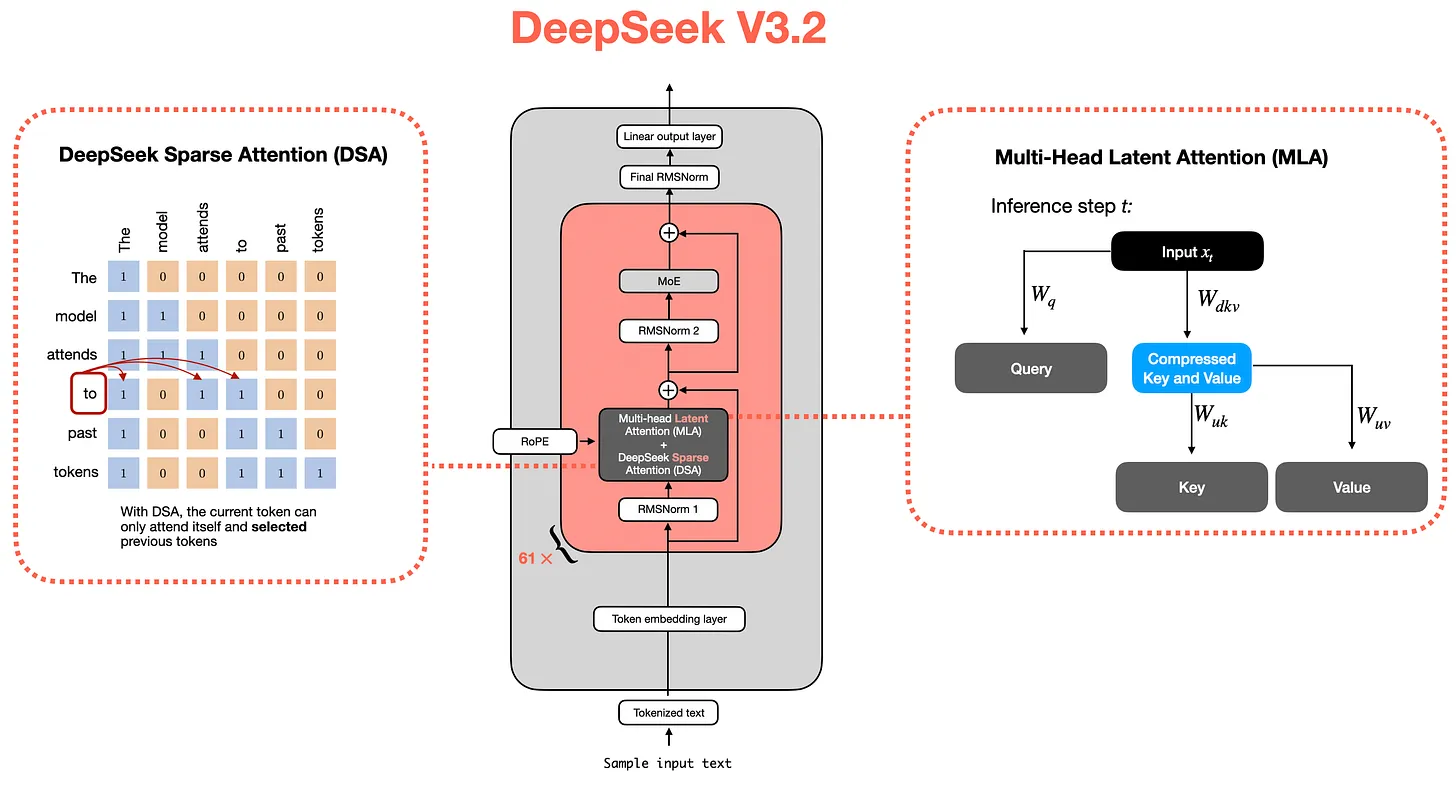
我原本打算在本文中用一小节介绍 DeepSeek V3.2,但最终写成了一篇超 5000 字的长文,因此将其拆分为独立文章,链接如下: