计算机图形学9大核心任务:从3D渲染到虚拟人,解锁视觉魔法背后的技术逻辑
打开3A游戏,沉浸在光影逼真的虚拟世界;刷短视频,被灵动的虚拟数字人吸引;看医疗影像,精准的病灶可视化辅助诊断 —— 这些震撼的视觉体验,背后都离不开计算机图形学(CG)的支撑。从实时渲染到虚拟交互,从科学可视化到数字孪生,计算机图形学早已渗透生活、工业、医疗等多个领域。今天就拆解它的 9 大核心任务,带你看懂视觉魔法背后的技术逻辑。
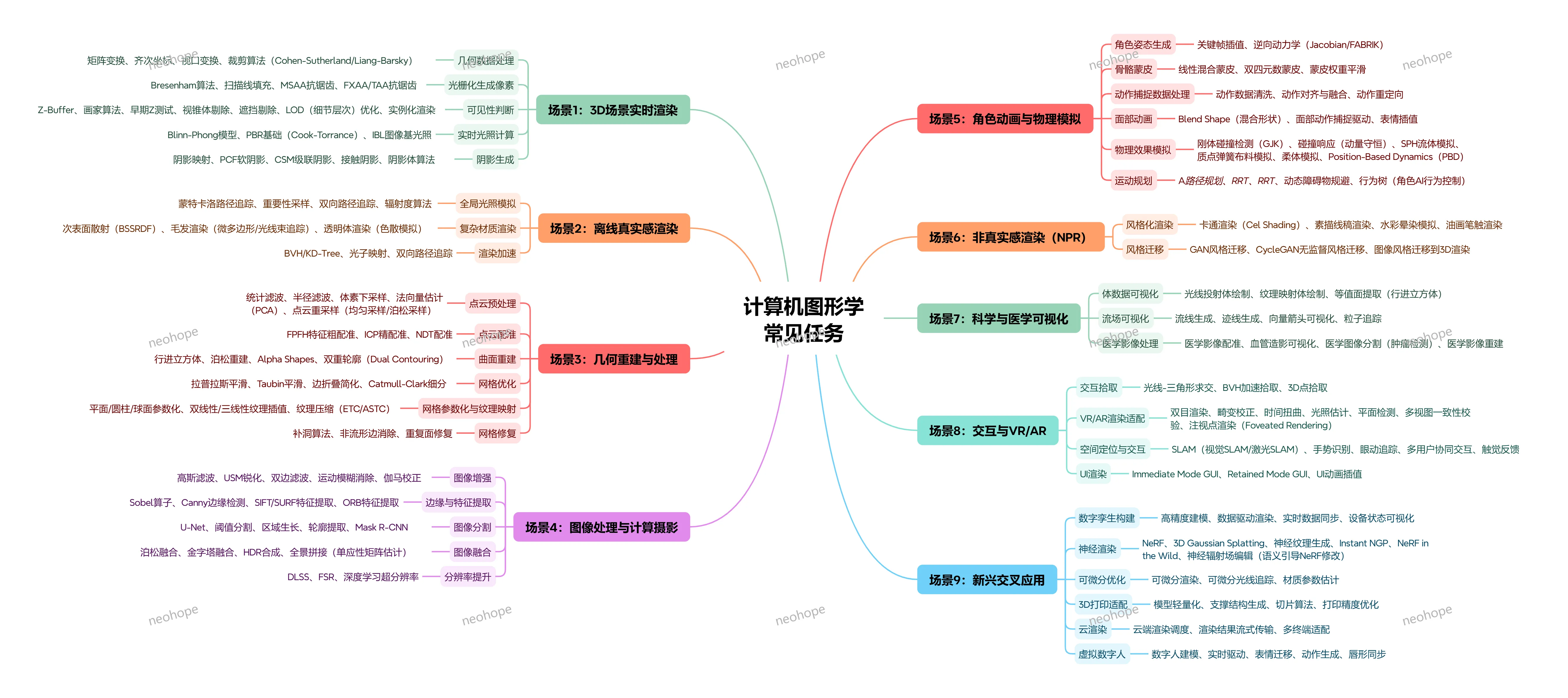
一、3D场景实时渲染:让虚拟世界 “即时可见”
核心目标:在游戏、VR/AR 等实时场景中,快速生成高质量图像,兼顾流畅度与视觉效果,是图形学最基础也最核心的任务。
1、几何数据处理:通过矩阵变换、齐次坐标转换、视口变换等技术,将 3D 模型映射到 2D 屏幕;用裁剪算法(Cohen-Sutherland/Liang-Barsky)剔除屏幕外的图形,提升效率;
2、光栅化与抗锯齿:用 Bresenham 算法绘制线条、扫描线填充图形,将几何形状转化为像素;通过 MSAA、FXAA/TAA 等抗锯齿技术,解决画面锯齿感,让边缘更平滑;
3、光照与阴影:用 Blinn-Phong 模型、PBR 基础(Cook-Torrance)、IBL 图像基光照模拟真实光影效果;通过阴影映射、PCF 软阴影、CSM 级联阴影等算法,生成自然的阴影,增强场景立体感;
4、可见性优化:用 Z-Buffer、画家算法、早期 Z 测试、LOD 细节层次优化、实例化等技术,只渲染屏幕可见的内容,减少无效计算,保障实时流畅。
二、离线真实感渲染:追求 “以假乱真” 的极致视觉
核心目标:在影视动画、广告特效等非实时场景中,生成照片级真实的图像,不追求速度,只追求视觉精度。
1、全局光照模拟:通过蒙特卡洛路径追踪、重要性采样、双向路径追踪、辐射度算法,模拟光线在场景中的多次反射与折射,还原真实世界的光照效果;
2、复杂材质渲染:针对毛发、布料、透明物体等复杂材质,用次表面散射(SSS)、毛发渲染、微边形 / 光透射体渲染等技术,还原材质的真实质感;
3、渲染加速:用 BVH/KD-Tree、光子映射等算法优化光线追踪效率,在保证效果的同时缩短渲染时间。
三、几何重建与处理:从点云到模型,构建虚拟几何基础
核心目标:将现实世界的物体或数据(如点云)转化为计算机可处理的 3D 模型,并优化模型质量,适配不同场景需求。
1、点云处理:先通过统计滤波、体素下采样等进行点云预处理,再用 ICP 精配准、NDT 配准、FFH 特征点配准等技术,将多帧点云对齐;
2、曲面重建:用行进立方体、泊松重建、Alpha Shapes、双重轮廓(Dual Contouring)等算法,从点云或体数据中生成连续的 3D 曲面;
3、网格优化与修复:通过拉普拉斯平滑、Taubin 平滑优化模型表面;用边折叠简化模型复杂度(适配实时场景),用 Catmull-Clark 细分提升模型细节;还能通过补洞算法、非流形边消除、重复面修复,解决模型破损问题;
4、网格参数化与纹理映射:将平面 / 圆柱 / 球面等参数化到网格上,通过双线性 / 三线性纹理插值、ETC/ASTC 纹理压缩技术,让纹理自然贴合模型。
四、图像处理与计算摄影:优化图像质量,创造特殊视觉效果
核心目标:对 2D 图像进行增强、分割、融合等处理,或通过算法模拟摄影效果,提升图像表现力。
1、图像增强:用高斯滤波降噪、USM 锐化提升细节、双边滤波保留边缘、运动模糊消除、伽马校正调整亮度,优化图像基础质量;
2、边缘与特征提取:通过 Sobel 算子、Canny 边缘检测,快速定位图像边缘;用 SIFT、SURF、ORB 等算法提取图像特征,用于匹配、追踪等场景;
3、图像分割与提取:用阈值分割、区域生长、轮廓提取等传统算法,或 U-Net、Mask R-CNN 等深度学习算法,精准分割图像中的目标(如医疗影像中的病灶);
4、图像融合与特效:实现图像拼接、全景合成、HDR 融合,生成宽视角或高动态范围图像;还能通过深度学习超分辨率(DLSS、FSR)提升图像分辨率,还原更多细节。
五、角色动画与物理模拟:让虚拟角色 “活起来”
核心目标:让 3D 角色拥有自然的动作和物理交互效果,适配游戏、动画、虚拟人等场景。
1、角色姿态与动画生成:通过关键帧插值、逆向动力学(Jacobian/FABRK)生成流畅姿态;用骨骼蒙皮(线性混合蒙皮、双四元数蒙皮)让模型跟随骨骼运动,蒙皮权重平滑技术避免动作变形;
2、面部动画:用 Blend Shape(混合形状)实现丰富表情,通过面部动作捕捉驱动、表情插值,让虚拟角色的表情更自然逼真;
3、动作数据处理:对动作捕捉数据进行清洗、对齐与融合,还能实现动作重定向(将一个角色的动作迁移到另一个角色上);
4、物理效果模拟:用 GJK 算法实现刚体碰撞检测,通过动量守恒计算碰撞响应;用 SPH 流体模拟、质点弹簧布料模拟、柔体模拟、PBD(Position-Based Dynamics)等技术,还原液体、布料、软组织的真实物理行为;
5、运动规划:用 A路径规划、RRT、RRT算法让角色避开障碍物,通过行为树控制角色 AI 行为(如游戏中 NPC 的决策逻辑)。
六、非真实感渲染(NPR):打造 “风格化视觉”
核心目标:跳出真实感框架,生成卡通、素描、水彩等风格化图像,适配动画、插画、游戏等创意场景。
1、基础风格化渲染:用 Cel Shading(卡通渲染)生成动漫质感,通过素描线稿渲染模拟手绘线条,用水彩晕染模拟、油画笔触渲染还原艺术绘画效果;
2、风格迁移:借助 GAN 风格迁移、CycleGAN 无监督风格迁移技术,将 2D 图像的风格迁移到 3D 渲染中(如把照片风格转化为卡通风格的 3D 场景)。
七、科学与医学可视化:让 “无形数据” 可视化
核心目标:将科学计算数据(如流场)、医学影像数据(如 CT/MRI)转化为直观的视觉形式,辅助研究与诊断。
1、体数据可视化:用光线投射体绘制、纹理映射体绘制、等值面提取(行进立方体)等技术,呈现 CT、MRI 等医学体数据,让内部结构一目了然;
2、流场可视化:通过流线生成、迹线生成、向量箭头可视化、粒子追踪,直观展示气流、水流等流场的运动规律;
3、医学影像专项处理:实现医学影像配准(多模态影像对齐)、血管可视化、医学影像分割(肿瘤检测),为临床诊断和治疗提供支持。
八、交互与 VR/AR:打破虚拟与现实的边界
核心目标:实现人与虚拟环境的自然交互,适配 VR/AR、元宇宙等沉浸式场景。
1、空间定位与交互:通过 SLAM(视觉 SLAM、激光 SLAM)实现空间定位,结合手势识别、眼动追踪,让用户无需控制器即可操作;还支持多用户协同交互、触觉反馈,提升沉浸感;
2、VR/AR渲染适配:采用双目渲染模拟人眼视角差,通过畸变校正、时间扭曲解决画面延迟问题;结合光照估计、平面检测、多视图一致性校验,让虚拟物体与现实环境自然融合;注视点渲染(Foveated Rendering)技术可优化性能,只高清渲染注视区域;
3、GUI 与交互拾取:用 Immediate Mode GUI、Retained Mode GUI 构建虚拟界面,通过 GUI 动画插值提升交互体验;通过光线三角形求交、BVH 加速拾取,实现 3D 点精准拾取(如点击虚拟物体触发事件)。
九、新兴交叉应用:图形学与新技术的融合创新
核心目标:结合 AI、云计算、3D 打印等技术,拓展图形学的应用边界,催生新场景、新体验。
1、虚拟数字人:整合数字人建模、实时驱动、表情迁移、动作生成、唇形同步等技术,打造能实时交互的虚拟人(如直播、客服场景);
2、数字孪生:通过高精度建模、数据驱动渲染、实时数据同步、设备状态可视化,构建物理世界的虚拟映射(如工业设备监控、城市规划);
3、神经渲染与可微分优化:用 NeRF 等神经渲染技术,从 2D 图像重建 3D 场景;通过可微分渲染、可微分光线追踪,实现材质参数估计等精准优化;
4、云渲染与 3D 打印适配:云端渲染调度技术可将复杂渲染任务放在云端,渲染结果流式传输到终端,适配低性能设备;3D 打印适配技术则能实现模型轻量化、支撑结构生成、切片算法优化,提升打印精度。
总结:计算机图形学的核心逻辑 ——“将虚拟落地,让现实升级”
从实时渲染到虚拟交互,从数据可视化到数字孪生,计算机图形学的本质是 “用技术构建视觉桥梁”—— 让虚拟世界更逼真、让无形数据更直观、让现实体验更丰富。
随着 AI、云计算、VR/AR 等技术的发展,计算机图形学的应用场景还在不断拓展:从游戏动画到工业制造,从医疗诊断到元宇宙,它正在用视觉魔法改变我们感知世界、交互世界的方式。
你在生活中接触过哪些让你惊艳的图形学应用?欢迎在评论区分享你的体验~