在单机文件系统中,删除文件是一个“即时生效”的动作:执行删除操作后,文件元数据直接清除、磁盘空间立刻释放,逻辑简单、用户感知直观。但在大数据分布式集群中,这一逻辑不再适用,也是最容易让开发者产生认知偏差的核心点。
如果针对亿级小文件采用“即时物理删除”机制,会瞬间产生海量随机IO、频繁的元数据变更、大规模块数据清理动作,直接引发集群IO抖动、节点负载飙升、读写任务阻塞,严重破坏集群稳定性。
Learn and share.
在单机文件系统中,删除文件是一个“即时生效”的动作:执行删除操作后,文件元数据直接清除、磁盘空间立刻释放,逻辑简单、用户感知直观。但在大数据分布式集群中,这一逻辑不再适用,也是最容易让开发者产生认知偏差的核心点。
如果针对亿级小文件采用“即时物理删除”机制,会瞬间产生海量随机IO、频繁的元数据变更、大规模块数据清理动作,直接引发集群IO抖动、节点负载飙升、读写任务阻塞,严重破坏集群稳定性。
寻址,是数据读写的核心链路,也最能体现大数据分布式系统与传统单机系统的设计取舍。
在单机时代,文件寻址遵循“路径直连”逻辑:文件路径对应唯一inode,操作系统直接定位磁盘扇区,链路短、开销小、速度快。但这套逻辑完全无法适配大数据海量小文件场景——如果亿级小文件都依靠“直连寻址”,中心元数据节点极易成为瓶颈,集群调度、读写IO会导致严重延迟。
因此,所有主流大数据系统都做出了统一的核心取舍:牺牲单次寻址的极致速度,用多层索引、分层过滤、元数据跳转的微小计算开销,换取整个集群的稳定性与无限伸缩性。
在大数据分布式存储场景中,小文件是业界公认的“甜蜜的毒药”。单个KB级小文件体量微小、读写开销极低,看似不会对集群造成压力,但当业务持续迭代,千万级、亿级小文件批量堆积后,会引发一系列连锁集群故障:撑爆元数据节点内存、大幅拖垮集群整体读写性能、造成计算任务调度拥堵,严重时直接导致整个大数据集群服务瘫痪。
小文件治理的核心痛点,并非单文件数据量过小,而是传统单机文件的独立存储逻辑,完全不适用于分布式海量数据架构。单机场景下的小文件独立存储、独立管理模式,会无限放大分布式集群的元数据压力、存储冗余、计算调度缺陷。
基于此,HDFS、Hive、HBase、Ceph、Iceberg、Delta Lake、Hudi等所有主流大数据存储系统,针对小文件存储形成了统一的核心优化思路:彻底杜绝小文件以独立文件形态落地,通过文件打包、数据转译、结构化元数据管理、增量追加写入等方式,从根源减少物理文件数量,消解元数据膨胀隐患。不同系统因适配的业务场景不同,小文件存储的底层实现逻辑存在显著差异,本章节将深度拆解各主流系统的小文件存储机制。

Flink 是一个开源的流处理框架,旨在处理无界和有界数据流,凭借其流批一体的设计、高性能的执行引擎和完善的容错机制,成为当前实时计算领域的主流技术。本文介绍了 Flink 的功能、特点及其核心架构与算法。
在大数据处理领域,Spark早已成为不可或缺的核心引擎。自2009年诞生于加州大学伯克利分校的AMPLab,到2014年成为Apache基金会顶级项目,Spark凭借其卓越的性能和灵活的架构,逐步取代传统MapReduce,成为数千家企业(包括80%的财富500强)处理大规模数据的首选框架。今天,我们就来全面拆解Spark的核心功能、独特特点、核心架构、数据抽象、算法机制、核心组件、优化技术、生态集成及演进趋势,带你读懂这款“大规模数据分析的统一引擎”背后的底层逻辑。
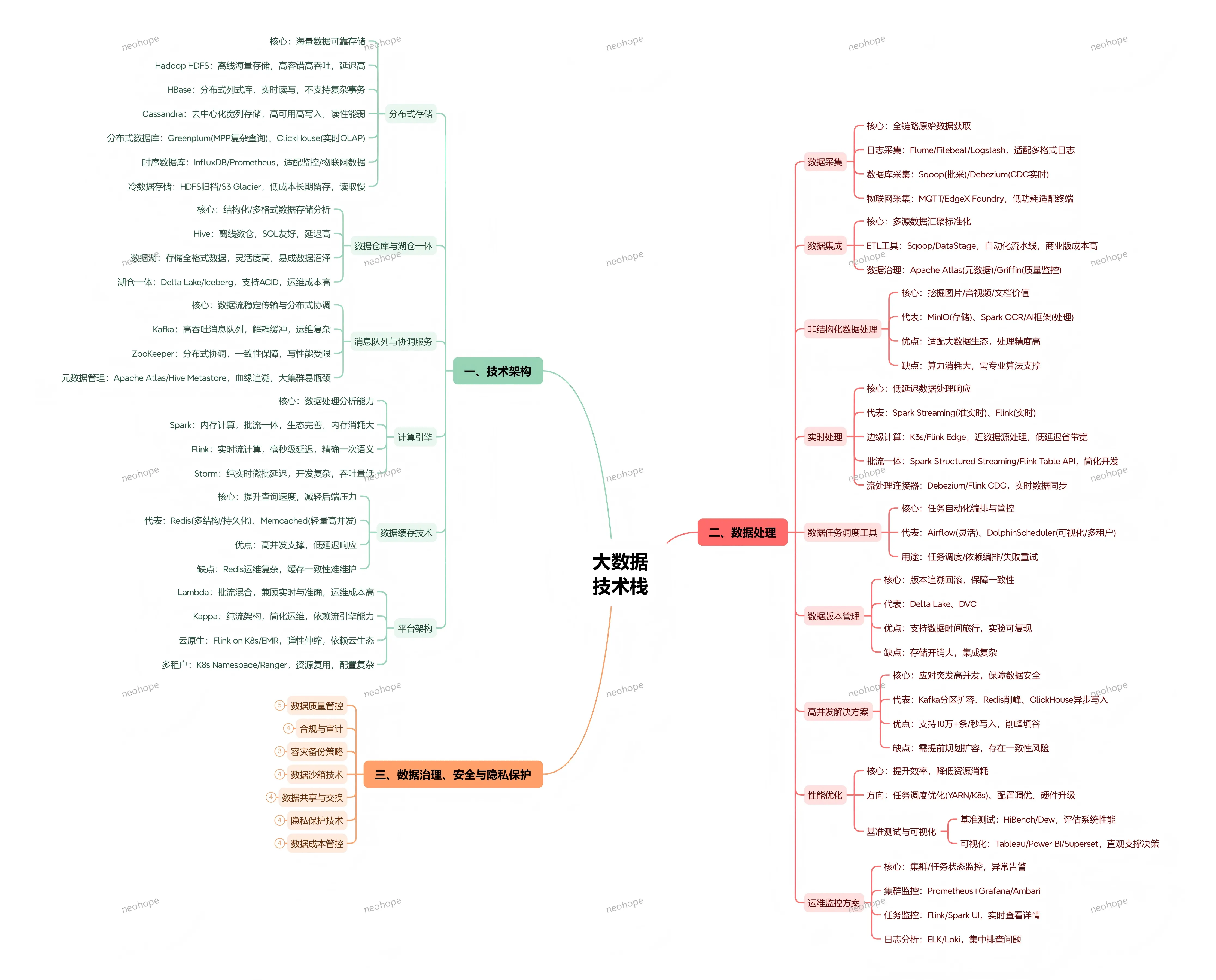
大数据技术栈是支撑海量、多源、异构数据完成从采集、存储、处理、分析到价值落地全生命周期的技术体系,核心解决传统技术无法应对的 “大容量、高速度、多类型” 数据处理难题,整体可分为技术架构、数据处理流程、治理与安全三大核心板块,当前正朝着湖仓一体、批流融合、云原生化的方向持续演进。
1、确保cdt01可以ssh联通cdt02和cdt03
#这个userid与可以无密码使用sudo的userid相同 ssh -l userid cdh02 ssh -l userid cdh03
2、浏览器访问(以后都是界面了)
http://172.16.172.101:7180
用户名:admin
密码:admin
3、根据引导界面,新建Cluster
将172.16.172.101-172.16.172.103都安装好cloudera-manager-agent
4、根据引导界面,选用需要的软件进行安装
安装时,注意合理分配角色,也就是合理分配内存资源
5、依次安装
hdfs
zookeeper
hbase
yarn
hive
spark
6、安装完毕
PS:
1、如果出现找不到jdbc driver的情况
sudo apt-get install libmysql-java
1、cdt01安装
#添加cloudera仓库 wget https://archive.cloudera.com/cm6/6.3.0/ubuntu1804/apt/archive.key sudo apt-key add archive.key wget https://archive.cloudera.com/cm6/6.3.0/ubuntu1804/apt/cloudera-manager.list sudo mv cloudera-manager.list /etc/apt/sources.list.d/ #更新软件清单 sudo apt-get update #安装jdk8 sudo apt-get install openjdk-8-jdk #安装cloudera sudo apt-get install cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server
2、安装及配置mysql
2.1、安装mysql
sudo apt-get install mysql-server mysql-client libmysqlclient-dev libmysql-java
2.2、停止mysql
sudo service mysql stop
2.3、删除不需要的文件
sudo rm /var/lib/mysql/ib_logfile0 sudo rm /var/lib/mysql/ib_logfile1
2.4、修改配置文件
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf #修改或添加以下信息 [mysqld] transaction-isolation = READ-COMMITTED max_allowed_packet = 32M max_connections = 300 innodb_flush_method = O_DIRECT
2.5、启动mysql
sudo service mysql start
2.6、初始化mysql
sudo mysql_secure_installation
3、创建数据库并授权
sudo mysql -uroot -p
-- 创建数据库 -- Cloudera Manager Server CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- Activity Monitor CREATE DATABASE amon DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- Reports Manager CREATE DATABASE rman DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- Hue CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- Hive Metastore Server CREATE DATABASE hive DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- Sentry Server CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- Cloudera Navigator Audit Server CREATE DATABASE nav DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- Cloudera Navigator Metadata Server CREATE DATABASE navms DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- Oozie CREATE DATABASE oozie DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; #创建用户并授权 GRANT ALL ON scm.* TO 'scm'@'%' IDENTIFIED BY 'scm123456'; GRANT ALL ON amon.* TO 'amon'@'%' IDENTIFIED BY 'amon123456'; GRANT ALL ON rman.* TO 'rman'@'%' IDENTIFIED BY 'rman123456'; GRANT ALL ON hue.* TO 'hue'@'%' IDENTIFIED BY 'hue123456'; GRANT ALL ON hive.* TO 'hive'@'%' IDENTIFIED BY 'hive123456'; GRANT ALL ON sentry.* TO 'sentry'@'%' IDENTIFIED BY 'sentry123456'; GRANT ALL ON nav.* TO 'nav'@'%' IDENTIFIED BY 'nav123456'; GRANT ALL ON navms.* TO 'navms'@'%' IDENTIFIED BY 'navms123456'; GRANT ALL ON oozie.* TO 'oozie'@'%' IDENTIFIED BY 'oozie123456';
4、初始化数据库
sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm scm scm123456 sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql amon amon amon123456 sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql rman rman rman123456 sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql hue hue hue123456 sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql hive hive hive123456 sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql sentry sentry sentry123456 sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql nav nav nav123456 sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql navms navms navms123456 sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql oozie oozie oozie123456
5、启动
#启动cloudera-scm-server sudo systemctl start cloudera-scm-server #查看启动日志,等待Jetty启动完成 sudo tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log
6、启动
浏览器访问
http://172.16.172.101:7180
用户名:admin
密码:admin
1、环境准备
VirtualBox 6 Ubuntu 18 Cloudera CDH 6.3
2、虚拟机安装Ubuntu18,配置为
1CPU
4G内存
300G硬盘
两块网卡,一块为HostOnly,一块为NAT
3、将虚拟机克隆为三份
如果是手工拷贝,记得修改硬盘UUID、虚拟机UUID、网卡硬件ID
4、设置IP地址、hostname及hosts文件
| 机器名 | HostOnly IP |
| cdh01 | 172.16.172.101 |
| cdh02 | 172.16.172.102 |
| cdh03 | 172.16.172.103 |
5、允许无密码使用sudo,至少修改cdh02和cdh03
#edit /etc/sudoers userid ALL=(ALL:ALL) NOPASSWD: ALL
1、下载安装脚本
wget -O bootstrap.sh https://raw.githubusercontent.com/getredash/redash/master/setup/ubuntu/bootstrap.sh
2、运行脚本
chmod +x bootstrap.sh sudo ./bootstrap.sh
3、脚本执行成功后,直接访问nginx就好了
http://ip:80
实际上是代理了这个网站
http://localhost:5000
4、常见问题
在执行过程中,遇到下载失败的情况,就直接把文件下载到本地,改一下路径,重新运行脚本就好了
我在运行脚本的过程中,遇到了缺少schema的提示,删除了数据库redash及用户redash,重新运行脚本就好了