前几天同事和我沟通,希望用工作流类似的功能,对现有的任务进行管理。
说实话,我实在不看好openkm的工作流管理功能(jbpm),但周末还是花了一些时间看了一下。
不看还不知到,看了以后才发现,OpenKM6已经有较长一段时间没有进行框架升级了,还都停留在JDK7早期时代,并且用到了GWt技术。
OpenKM6的工作流,用的是jbpm-3.3.1.GA。看了一下jboss上的jbpm项目,已经进化到jbpm6,好歹开始拥抱drools了吧。
额,扯远了。回到正题。
一、首先是开发环境的搭建,要到这里来下载哦
https://sourceforge.net/projects/openkmportabledev/?source=directory
如果你嫌麻烦,建议就直接解压到指定文件夹就可以用了。
二、打开eclipse,编译jbpm项目
是基于mvn的,有一些jar包,在openkm的仓库里,但下载不到,啥意思吗。自己google咯,还好不算多。
三、编译的时候,建议看下openkm的相关教程,超级简单
https://docs.openkm.com/kcenter/view/wfg/sample-workflow-execution.html
四、介绍一下几个常用节点:
start:工作流的起点,一个流程只允许一个起点
end:工作流的终点,可以有多个,但只要有一个到达终点,流程就结束了
fork、join:就是任务分支与状态同步啦
decision:选择
node:自动处理的任务节点
task node:需要人工干预的任务节点,数据的输入是通过表单form完成的
mail node:自动进行邮件处理的几点
transition:就是两个节点之间的连线
五、构建一个自己的工作流
1、新建一个工作流项目
2、会自动新建一个工作流,打开XXX.jpdl.xml文件,就可以进行编辑了
通过编辑器,自己画一个工作流,会自动生成两个文件,加上刚才的文件一共有三个文件:
XXX.jpdl.xml 节点定义及流程描述
.XXX.gpd.xml 元素的位置信息
XXX.jpg 工作流截图
在发布工作流的时候,这三个文件都要带上
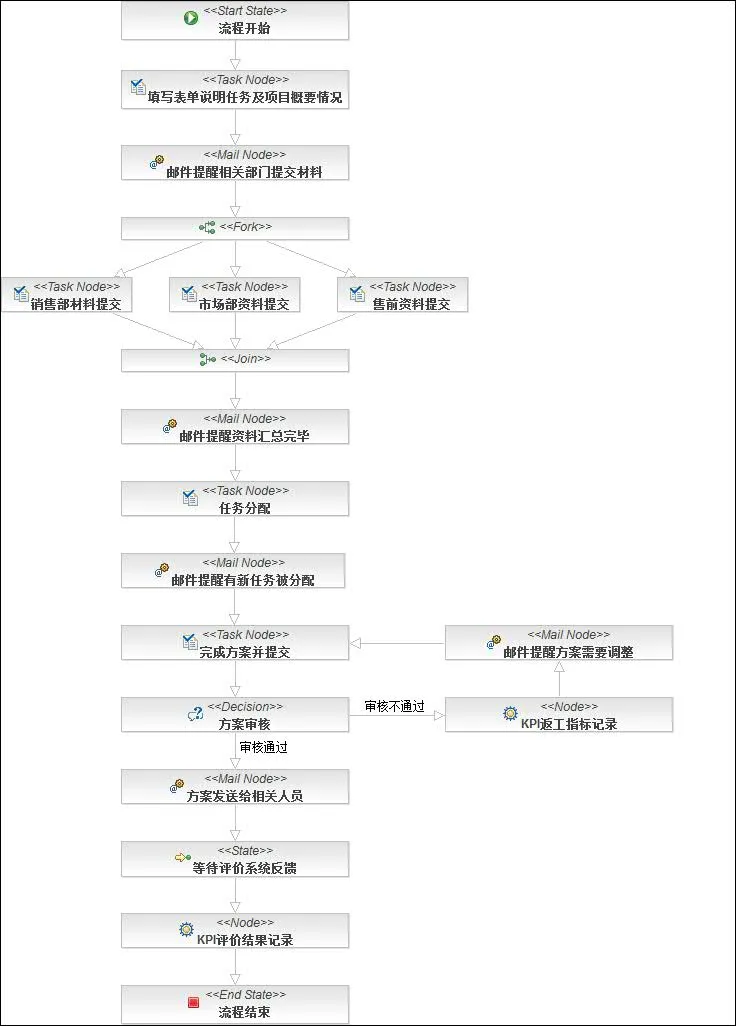
六、写Handler
编辑器上,可以直接处理的操作,其实很有限,也没有太多功能,主要还是靠编码实现。
编码的话,主要是实现几类接口:
org.jbpm.graph.def.ActionHandler:
多数的Handler,都用这个即可,包括transition、mail node、task node、node等
org.jbpm.taskmgmt.exe.Assignable:
主要用于任务执行者的分配
org.jbpm.graph.node.DecisionHandler:
主要用于选择节点
Handeler都只需要实现对于的方法即可。最后,通过编辑器进行配置。
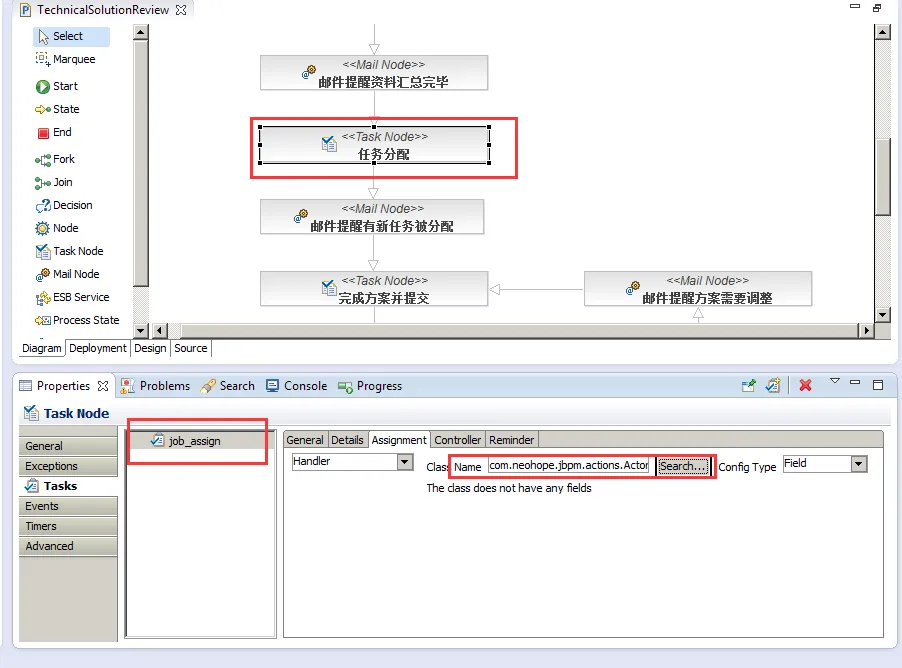
六、发布工作流
发布也很简单,就是直接用eclipse上的jbpm菜单就可以发布了,但要把参数配置好才行
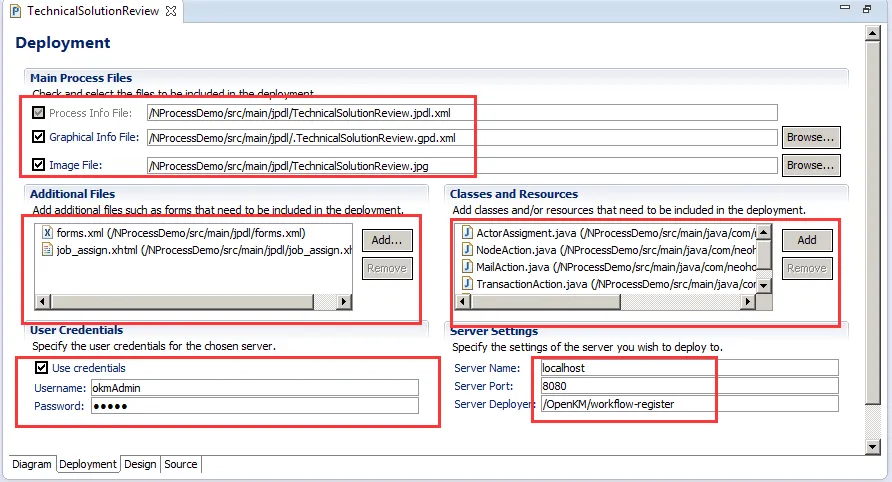
七、执行
1、首先要到openkm的后台,将工作流启用
2、然后找到任意一个文件、文件夹,执行工作流即可
八、填坑
遇到的最大的坑,莫过于字符集问题,我这边的方法,只修正了.XXX.gpd.xml的字符集问题,form的字符集问题,并没有修正
找到文件org.jbpm.gd.jpdl_3.4.1.v20120717-1252-H7-GA-SOA.jar,替换掉文件AbstractContentProvider.class即可
AbstractContentProvider.java源码如下:
package org.jbpm.gd.common.editor;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.io.UnsupportedEncodingException;
import java.io.Writer;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.eclipse.core.resources.IFile;
import org.eclipse.core.resources.IProject;
import org.eclipse.core.runtime.CoreException;
import org.eclipse.core.runtime.IPath;
import org.eclipse.draw2d.geometry.Dimension;
import org.eclipse.draw2d.geometry.Point;
import org.eclipse.draw2d.geometry.Rectangle;
import org.eclipse.jface.dialogs.MessageDialog;
import org.eclipse.ui.IEditorInput;
import org.eclipse.ui.IFileEditorInput;
import org.eclipse.ui.part.FileEditorInput;
import org.jbpm.gd.common.model.NamedElement;
import org.jbpm.gd.common.model.SemanticElement;
import org.jbpm.gd.common.notation.AbstractNodeContainer;
import org.jbpm.gd.common.notation.BendPoint;
import org.jbpm.gd.common.notation.Edge;
import org.jbpm.gd.common.notation.Label;
import org.jbpm.gd.common.notation.Node;
import org.jbpm.gd.common.notation.NodeContainer;
import org.jbpm.gd.common.notation.NotationElement;
import org.jbpm.gd.common.notation.NotationElementFactory;
import org.jbpm.gd.common.notation.NotationMapping;
import org.jbpm.gd.common.notation.RootContainer;
import org.jbpm.gd.jpdl.Logger;
public abstract class AbstractContentProvider implements ContentProvider {
protected abstract SemanticElement getEdgeSemanticElement(Node paramNode,
Element paramElement, int paramInt);
protected abstract SemanticElement getNodeSemanticElement(
NodeContainer paramNodeContainer, Element paramElement, int paramInt);
protected abstract void addNodes(NodeContainer paramNodeContainer,
Element paramElement);
protected abstract void addEdges(Node paramNode, Element paramElement);
protected abstract SemanticElement findDestination(Edge paramEdge,
Node paramNode);
protected String getRootNotationInfoElement() {
return "<root-container/>";
}
protected String createInitialNotationInfo() {
StringBuffer buffer = new StringBuffer();
buffer.append("<?xml version=\"1.0\" encoding=\"UTF-8\"?>");
buffer.append("\n\n");
buffer.append(getRootNotationInfoElement());
return buffer.toString();
}
public String getNotationInfoFileName(String semanticInfoFileName) {
return ".gpd." + semanticInfoFileName;
}
public String getDiagramImageFileName(String semanticInfoFileName) {
int index = semanticInfoFileName.indexOf(".xml");
String result = index > -1 ? semanticInfoFileName.substring(0, index)
: semanticInfoFileName;
return result + ".jpg";
}
protected void processRootContainer(RootContainer rootContainer,
Element notationInfo) {
addDimension(rootContainer, notationInfo);
addNodes(rootContainer, notationInfo);
postProcess(rootContainer);
}
protected void addNodes(NodeContainer nodeContainer,
SemanticElement[] semanticElements, Element notationInfo) {
List notationInfoElements = notationInfo == null ? new ArrayList()
: notationInfo.elements();
for (int i = 0; i < semanticElements.length; i++) {
Element notationInfoElement = null;
String nodeName = ((NamedElement) semanticElements[i]).getName();
for (int j = 0; j < notationInfoElements.size(); j++) {
Element element = (Element) notationInfoElements.get(j);
String elementName = element.attributeValue("name");
if (((elementName != null) && (elementName.equals(nodeName)))
|| ((elementName == null) && (nodeName == null))) {
notationInfoElement = element;
}
}
addNode(nodeContainer, semanticElements[i], notationInfoElement);
}
}
protected void addEdges(Node node, SemanticElement[] semanticElements,
Element notationInfo) {
List notationInfoElements = notationInfo == null ? new ArrayList()
: notationInfo.elements();
for (int i = 0; i < semanticElements.length; i++) {
Element notationInfoElement = null;
if (notationInfoElements.size() >= i + 1) {
notationInfoElement = (Element) notationInfoElements.get(i);
}
addEdge(node, semanticElements[i], notationInfoElement);
}
}
protected void addNode(NodeContainer nodeContainer,
SemanticElement semanticElement, Element notationInfoElement) {
String notationElementId = NotationMapping
.getNotationElementId(semanticElement.getElementId());
Node notationElement = (Node) nodeContainer.getFactory().create(
notationElementId);
notationElement.setSemanticElement(semanticElement);
notationElement.register();
nodeContainer.addNode(notationElement);
semanticElement.addPropertyChangeListener(notationElement);
processNode(notationElement, notationInfoElement);
if ((notationElement instanceof NodeContainer)) {
addNodes((NodeContainer) notationElement, notationInfoElement);
}
}
protected void addEdge(Node node, SemanticElement semanticElement,
Element notationInfoElement) {
NotationElement notationElement = node
.getRegisteredNotationElementFor(semanticElement);
if (notationElement == null) {
String notationElementId = NotationMapping
.getNotationElementId(semanticElement.getElementId());
notationElement = node.getFactory().create(notationElementId);
notationElement.setSemanticElement(semanticElement);
notationElement.register();
node.addLeavingEdge((Edge) notationElement);
semanticElement.addPropertyChangeListener(notationElement);
}
processEdge((Edge) notationElement, notationInfoElement);
}
protected void addDimension(RootContainer processDefinitionNotationElement,
Element processDiagramInfo) {
String width = processDiagramInfo.attributeValue("width");
String height = processDiagramInfo.attributeValue("height");
Dimension dimension = new Dimension(width == null ? 0 : Integer
.valueOf(width).intValue(), height == null ? 0 : Integer
.valueOf(height).intValue());
processDefinitionNotationElement.setDimension(dimension);
}
protected void processNode(Node node, Element notationInfoElement) {
addConstraint(node, notationInfoElement);
addEdges(node, notationInfoElement);
}
protected void processEdge(Edge edge, Element edgeInfo) {
processLabel(edge, edgeInfo);
addBendpoints(edge, edgeInfo);
}
protected void addBendpoints(Edge edge, Element edgeInfo) {
if (edgeInfo != null) {
List list = edgeInfo.elements("bendpoint");
for (int i = 0; i < list.size(); i++) {
addBendpoint(edge, (Element) list.get(i), i);
}
}
}
protected BendPoint addBendpoint(Edge edge, Element bendpointInfo, int index) {
BendPoint result = new BendPoint();
processBendpoint(result, bendpointInfo);
edge.addBendPoint(result);
return result;
}
protected void processBendpoint(BendPoint bendPoint, Element bendpointInfo) {
int w1 = Integer.valueOf(bendpointInfo.attributeValue("w1")).intValue();
int h1 = Integer.valueOf(bendpointInfo.attributeValue("h1")).intValue();
int w2 = Integer.valueOf(bendpointInfo.attributeValue("w2")).intValue();
int h2 = Integer.valueOf(bendpointInfo.attributeValue("h2")).intValue();
Dimension d1 = new Dimension(w1, h1);
Dimension d2 = new Dimension(w2, h2);
bendPoint.setRelativeDimensions(d1, d2);
}
private void processLabel(Edge edge, Element edgeInfo) {
Element label = null;
if (edgeInfo != null) {
label = edgeInfo.element("label");
}
if (label != null) {
Point offset = new Point();
offset.x = Integer.valueOf(label.attributeValue("x")).intValue();
offset.y = Integer.valueOf(label.attributeValue("y")).intValue();
edge.getLabel().setOffset(offset);
}
}
private void addConstraint(Node node, Element nodeInfo) {
Rectangle constraint = node.getConstraint().getCopy();
Dimension initialDimension = NotationMapping.getInitialDimension(node
.getSemanticElement().getElementId());
if (initialDimension != null) {
constraint.setSize(initialDimension);
}
if (nodeInfo != null) {
constraint.x = Integer.valueOf(nodeInfo.attributeValue("x"))
.intValue();
constraint.y = Integer.valueOf(nodeInfo.attributeValue("y"))
.intValue();
constraint.width = Integer
.valueOf(nodeInfo.attributeValue("width")).intValue();
constraint.height = Integer.valueOf(
nodeInfo.attributeValue("height")).intValue();
}
node.setConstraint(constraint);
}
protected void postProcess(NodeContainer nodeContainer) {
List nodes = nodeContainer.getNodes();
for (int i = 0; i < nodes.size(); i++) {
Node node = (Node) nodes.get(i);
List edges = node.getLeavingEdges();
for (int j = 0; j < edges.size(); j++) {
Edge edge = (Edge) edges.get(j);
SemanticElement destination = findDestination(edge, node);
Node target = (Node) edge.getFactory()
.getRegisteredNotationElementFor(destination);
if ((target != null) && (edge.getTarget() == null)) {
target.addArrivingEdge(edge);
}
}
if ((node instanceof NodeContainer)) {
postProcess((NodeContainer) node);
}
}
}
public boolean saveToInput(IEditorInput input, RootContainer rootContainer) {
boolean result = true;
try {
IFile file = getNotationInfoFile(((IFileEditorInput) input)
.getFile());
InputStreamReader reader = new InputStreamReader(file.getContents(), "UTF-8");
Element notationInfo = new SAXReader().read(reader)
.getRootElement();
if (upToDateCheck(notationInfo)) {
getNotationInfoFile(((IFileEditorInput) input).getFile())
.setContents(
new ByteArrayInputStream(toNotationInfoXml(
rootContainer).getBytes("UTF-8")),
true, true, null);
} else {
result = false;
}
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
protected String toNotationInfoXml(RootContainer rootContainer) {
StringWriter writer = new StringWriter();
write(rootContainer, writer);
return writer.toString();
}
protected void write(RootContainer rootContainer, Writer writer) {
try {
Document document = DocumentHelper.createDocument();
Element root = document.addElement("root-container");
write(rootContainer, root);
XMLWriter xmlWriter = new XMLWriter(writer,
OutputFormat.createPrettyPrint());
xmlWriter.write(document);
} catch (IOException e) {
e.printStackTrace(new PrintWriter(writer));
}
}
protected void write(RootContainer rootContainer, Element element) {
addAttribute(element, "name",
((NamedElement) rootContainer.getSemanticElement()).getName());
addAttribute(element, "width",
Integer.toString(rootContainer.getDimension().width));
addAttribute(element, "height",
Integer.toString(rootContainer.getDimension().height));
Iterator iter = rootContainer.getNodes().iterator();
while (iter.hasNext()) {
write((Node) iter.next(), element);
}
}
protected void write(Node node, Element element) {
Element newElement = null;
if ((node instanceof AbstractNodeContainer)) {
newElement = addElement(element, "node-container");
} else {
newElement = addElement(element, "node");
}
addAttribute(newElement, "name",
((NamedElement) node.getSemanticElement()).getName());
addAttribute(newElement, "x", String.valueOf(node.getConstraint().x));
addAttribute(newElement, "y", String.valueOf(node.getConstraint().y));
addAttribute(newElement, "width",
String.valueOf(node.getConstraint().width));
addAttribute(newElement, "height",
String.valueOf(node.getConstraint().height));
if ((node instanceof AbstractNodeContainer)) {
Iterator nodes = ((AbstractNodeContainer) node).getNodes()
.iterator();
while (nodes.hasNext()) {
write((Node) nodes.next(), newElement);
}
}
Iterator edges = node.getLeavingEdges().iterator();
while (edges.hasNext()) {
Edge edge = (Edge) edges.next();
write(edge, addElement(newElement, "edge"));
}
}
protected void write(Edge edge, Element element) {
Point offset = edge.getLabel().getOffset();
if (offset != null) {
Element label = addElement(element, "label");
addAttribute(label, "x", String.valueOf(offset.x));
addAttribute(label, "y", String.valueOf(offset.y));
}
Iterator bendpoints = edge.getBendPoints().iterator();
while (bendpoints.hasNext()) {
write((BendPoint) bendpoints.next(),
addElement(element, "bendpoint"));
}
}
protected void write(BendPoint bendpoint, Element bendpointElement) {
addAttribute(bendpointElement, "w1",
String.valueOf(bendpoint.getFirstRelativeDimension().width));
addAttribute(bendpointElement, "h1",
String.valueOf(bendpoint.getFirstRelativeDimension().height));
addAttribute(bendpointElement, "w2",
String.valueOf(bendpoint.getSecondRelativeDimension().width));
addAttribute(bendpointElement, "h2",
String.valueOf(bendpoint.getSecondRelativeDimension().height));
}
protected Element addElement(Element element, String elementName) {
Element newElement = element.addElement(elementName);
return newElement;
}
protected void addAttribute(Element e, String attributeName, String value) {
if (value != null) {
e.addAttribute(attributeName, value);
}
}
private void createNotationInfoFile(IFile notationInfoFile) {
try {
notationInfoFile.create(new ByteArrayInputStream(
createInitialNotationInfo().toString().getBytes("UTF-8")),
true, null);
} catch (CoreException e) {
Logger.logError(e);
} catch (UnsupportedEncodingException e) {
Logger.logError(e);
}
}
protected IFile getNotationInfoFile(IFile semanticInfoFile) {
IProject project = semanticInfoFile.getProject();
IPath semanticInfoPath = semanticInfoFile.getProjectRelativePath();
IPath notationInfoPath = semanticInfoPath.removeLastSegments(1).append(
getNotationInfoFileName(semanticInfoFile.getName()));
IFile notationInfoFile = project.getFile(notationInfoPath);
if (!notationInfoFile.exists()) {
createNotationInfoFile(notationInfoFile);
}
return notationInfoFile;
}
public void addNotationInfo(RootContainer rootContainer, IEditorInput input) {
try {
IFile file = getNotationInfoFile(((FileEditorInput) input)
.getFile());
if (file.exists()) {
InputStreamReader reader = new InputStreamReader(
file.getContents(),"UTF-8");
Element notationInfo = new SAXReader().read(reader)
.getRootElement();
boolean changed = convertCheck(notationInfo);
processRootContainer(rootContainer, notationInfo);
if (changed) {
file.setContents(
new ByteArrayInputStream(toNotationInfoXml(
rootContainer).getBytes("UTF-8")), true,
true, null);
}
} else {
file.create(new ByteArrayInputStream(
createInitialNotationInfo().toString()
.getBytes("UTF-8")), true, null);
}
} catch (DocumentException e) {
e.printStackTrace();
throw new RuntimeException(e);
} catch (CoreException e) {
e.printStackTrace();
throw new RuntimeException(e);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
private boolean convertCheck(Element notationInfo) {
boolean changed = false;
if (("process-diagram".equals(notationInfo.getName()))
|| ("pageflow-diagram".equals(notationInfo.getName()))) {
MessageDialog dialog = new MessageDialog(
null,
"Convert To 3.1.x Format",
null,
"A file created with an older GPD version was detected. If you open this file it will be converted to the 3.1.x format and overwritten.\nDo you want to continue?",
3, new String[] { "Convert And Open",
"Continue Without Converting" }, 0);
if (dialog.open() == 0) {
convertToRootContainer(notationInfo);
changed = true;
}
}
return changed;
}
private boolean upToDateCheck(Element notationInfo) {
if (("process-diagram".equals(notationInfo.getName()))
|| ("pageflow-diagram".equals(notationInfo.getName()))) {
MessageDialog dialog = new MessageDialog(
null,
"GPD 3.0.x Format Detected",
null,
"The file you are trying to save contains GPD 3.0.x information.Saving the file will result in an automatic conversion into the 3.1.x format.It will be impossible to open it with the old GPD.\nDo you want to continue?",
3, new String[] { "Save And Convert", "Cancel" }, 0);
return dialog.open() == 0;
}
return true;
}
private void convertToRootContainer(Element notationInfo) {
notationInfo.setName("root-container");
convertChildrenToEdge(notationInfo);
}
private void convertChildrenToEdge(Element element) {
List list = element.elements();
for (int i = 0; i < list.size(); i++) {
convertToEdge((Element) list.get(i));
}
}
private void convertToEdge(Element element) {
if ("transition".equals(element.getName())) {
element.setName("edge");
}
convertChildrenToEdge(element);
}
}
结语:
1、jbpm如果要用起来,还是要有很大的工作量的,而且早期版本对中文支持并不友好
2、openkm的工作流,整体来说太弱了,不够假单和直观
3、这种流程式管理方式,并不符合我们的管理方式
4、先用openkm的文档管理功能就好了
5、如果openkm再不升级框架,估计后面我们要找其他文档管理工具了。